

The future of (ads) privacy
The future of (ads) privacy
The seismic change brewing in the attention economy, and how Google, Apple and others will redesign a trillion-dollar paradigm

This is the first in a n-part series on data and privacy, areas I’ve worked in and written about for an inordinate amount of time.
For reasons I hope to make clear, we are on the verge of a once-in-a-generation step-change in how the human species, Homo sapiens iphonensis, interacts with data and thence the outside world. Please follow along or even subscribe(!) for the whole story.
Note: None of this should be taken as a big reveal of any company’s ads product strategy. What’s described here was first pioneered and implemented at my previous employer Branch Metrics (among other startups such as Brave). Not for the first time in Silicon Valley history, the majors are playing catchup to upstarts.
Therefore, what you have said in darkness will be heard in the daylight, and what you have whispered in private rooms will be shouted from the housetops.
-Luke 12:3
The reigning paradigm of Internet monetization, the fundamental architecture of an ecosystem that rakes in more than the GDP of Denmark per year and props up market caps in the literal trillions, is as simple as what’s depicted below:

A user interacts with a device—a ‘thin client’, to use slightly dated language—that merely provides the interface and generates local data soon to be beamed into the cloud. A user ID—a cookie, device ID, email, or something unique that indexes everything—follows along as the ‘primary key’ (to use database-speak) into this immense sea of online user data.
That key1 is then used to swap information among the various boxes in this retina-scarring map of the ad tech ecosystem.

The whole privacy game, as currently constructed, is simply the data dance around that user ID and accompanying behavioral data. That dance mostly exists because the ecosystem is so fragmented—contemplate again that patchwork quilt of logos—the various players need a common name for your data as the digital version of you makes its way through the monetization plumbing.
When you put an item in the shopping cart at Amazon, then blink away to another app, and then are served an ad for that item (which you ignore), and then finally buy the item via a different ad on a different app two days later, every link in that chain—Amazon, the other app you were using, the other-other app you were using, the company that sold the ad, the company that keeps track of in-app sales—all need to agree on a name for you, the consumer.
We have broken all laws of advertising physics: we have a product whose privacy profile is better which also monetizes better than the non-private version. This is a miracle on the order of Jesus with his loaves and fishes.
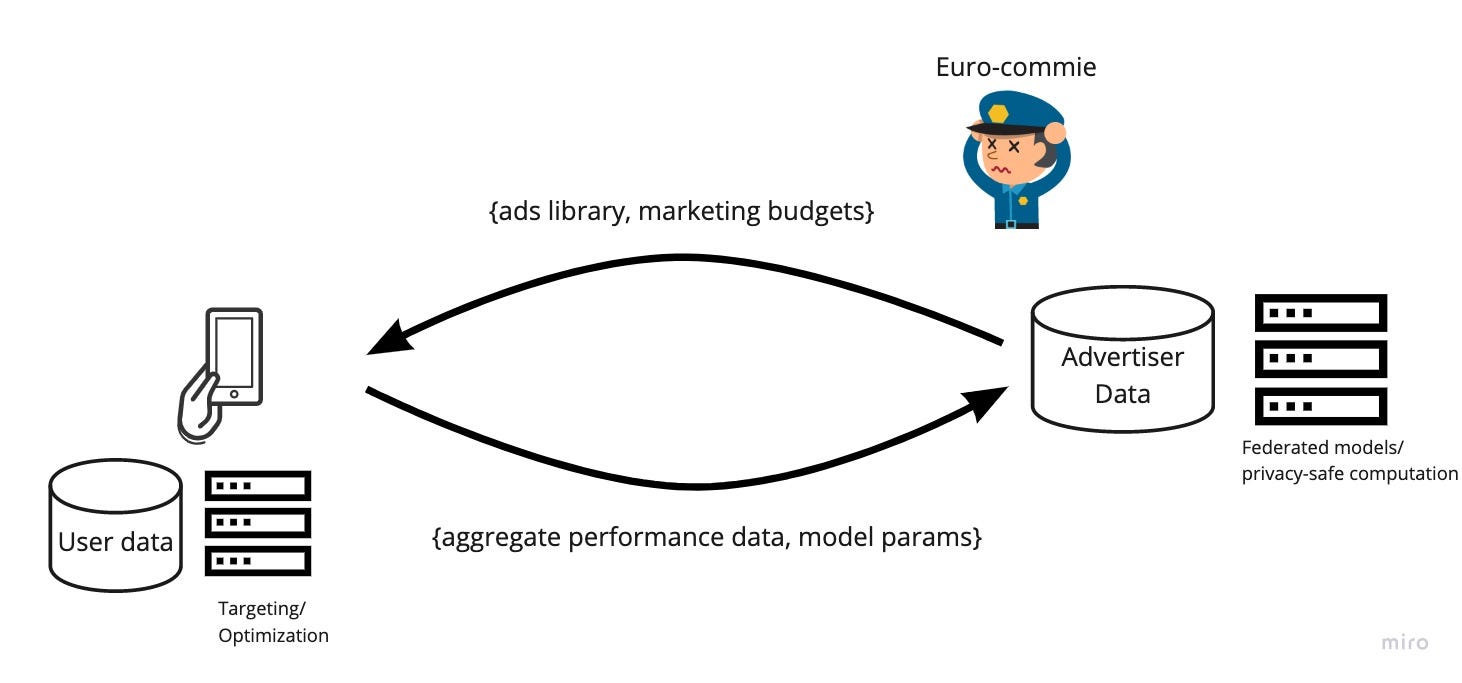
From the hard-nosed viewpoint of the marketer, all this endless privacy drama is some Euro-commie bullshit around that one column in the database table with a name like ‘aaid’ or ‘idfa’, whose other columns contain everything you do online. That special column that gets deleted (logically if not literally) when you finally hit that ‘opt out’ button that nags us all to death thanks to the “we can’t innovate, so we’ll regulate” European Union.
So…what if we got rid of the column?
What if, in fact, the data never leaves the device, such that we don’t need to store and index that data on the cloud side at all?
In that case, all the ponderous discussion in the General Data Protection Regulation (GDPR) around data ‘processors’ vs. ‘controllers’, or around ‘businesses’ and ‘service providers’ in the California Consumer Privacy Act (CCPA)—essentially, convoluted debates around first vs. third party uses of data—simply goes away. Ditto the obsession around ‘personal identifiers’ and how they’re trafficked around the convoluted ad tech game board above. The regulation which fixates on how your data gets into the cloud and how it’s labeled with your pseudonym….becomes entirely moot.
Just. Like. That.
But how would you do it? And how do we reproduce all the fancy and intrusive optimization and targeting that (reputedly at least) makes such consumerist slaves of every user on each and every smartphone?
As I learned doing this at my previous employer, the technical challenges are considerable. Moving the bulk of the logic and code from the cloud to the device is a major undertaking; it’s nothing less than inverting the entire architecture diagram, and running the bulk of your code on countless mobile devices rather than one (abstract) cloud server. To invert Francis Bacon’s Orientalist turn of phrase: if Muhammed can no longer go to the mountain due to GDPR regulations, well, then we’re going to have to make the mountain go to Muhammed instead (or his smartphone). And that means putting that entire set of boxes you see on the cloud side—the abstract version of that sea of third-party logos—somehow on the device itself.
For the developers out there, that means there’s no server you can log into to see what’s going on; there’s no master log you can search for an error output and figure out a bug; there’s no master repository of code you can ‘hotfix’ if you realize there’s a deep flaw in the logic.
Perhaps the best analogy is when NASA beams some updated instructions to the Voyager 1 probe—currently in interstellar space, one of the handful of human artifacts that have left the solar system—and many white-knuckle moments later, they receive some confirmatory reply saying the update went through.
WOOOT!
They didn’t brick the space probe whose hardware they couldn’t access if they really had to. But instead of one probe, there are hundreds of millions of devices globally. Finicky devices, often mid or low-market, running with flickering data connectivity and with two porn videos streaming in the background and thirty other apps open. I can tell you from my personal experience implementing such an inverted architecture, the teams at Google and elsewhere are in for a good time.
But it can be done, and is currently being done. Consider Google’s recent launch of the cutely-named FLoC (Federated Learning of Cohorts). Rather than spewing your Web browsing data hither and yon all over the above LumaScape, FLoC keeps your browsing data on our Chrome browser, and learns broader interest categories via code running on your browser itself. Sure, this involves browsers and they play a minor role these days compared to mobile apps, but for a company that has made literally hundreds of billions of dollars off browser cookies, this is a hugely telling move.
Google also isn’t lying when they tout the privacy upsides of all this.
It really, really is the case this is better for user privacy. You wanted a real opt-out you privacy paranoiac? Great…here’s an opt-out for you under this new paradigm: take your phone and throw it into the bay. There, you’ve really opted out. Marketers (or anyone else for that matter) know practically nothing about you now. Unlike all the bullshit opt-out buttons the Europeans imposed on us that never really delete you from the cloud, this well and truly makes your data disappear from the face of the Earth.
The skeptics might ask: But surely there’s some performance tradeoff in running that entire diagram of services off some little phone rather than the world’s repository of cloud servers? Surely there’s some degradation in either optimization, data quality, latency, or something else by not training models on the entire treasure trove of data at once in the cloud?
From the hard-nosed viewpoint of the marketer, all this endless privacy drama is some Euro-commie bullshit around one column in the database table.
So…what if we just got rid of that column?
On the contrary!
There’s more and richer data on the device than the ad tech machinery has ever had in the cloud. Consider the app usage stats that Android makes available to anyone running code with system-level permissions: that’s a level of fine-grained usage data nobody but an app publisher (and even then only for their app) would ever have access to. Not to mention all sorts of useful and timely stuff like network state, fine-grained geolocation, bluetooth connections, etc. The dark, dirty secret of much advertising data is that it’s stale or mismapped to the wrong user; if your targeting logic is running on the phone itself, it’s guaranteed to be correct and recent. No cloud data has ever been richer or better than this.
Sure, you’d have to rejigger a few things so that data from app A could be used (in a mutually-agreeable manner) to influence user experiences on app B (which already happens, but again via a cloud detour), but that’s just a bit of on-device plumbing that the operating system could handle. By putting the ad machinery on the device itself the advertiser has access to whatever app you touched and just about every other aspect of your actual mobile behavior….all while scrupulously following privacy law.
Consider this marvel!
We have broken all laws of advertising physics: we have a product whose privacy profile is better which also monetizes at least as well and very likely better than the non-private version. This is a miracle on the order of Jesus with his loaves and fishes: we just reach into the magical bag of smartphone data and pull out a cornucopia that we couldn’t have cooked up in a regular kitchen (and totes cool with privacy law!).
Like porn, advertising is the ruthlessly pragmatic (and quantitative) business willing to adopt any technology that yields a minor edge. The same way that porn pioneered online payment or video-streaming, ads will be the first industry to undertake this complete refactoring of how your data is used.
As with most problems in tech, the issues are really human ones: the entire business would have to be refactored along with the engineering. The only companies who can drive this foundational change are the two companies who control the smartphone operating systems themselves. Everyone else in that logo landscape, to a greater or lesser degree, plays a reduced role in the drama; some may no longer even have a role.
Again, just why the hell do we take all this data being generated by all these dozens of apps running on a device, and eat up huge network bandwidth getting it into the cloud, only to then pass back more state—decisions about products to show, images, ads, everything—back to the device to generate a user experience. Whose data (once again!) we send into the cloud for yet more computation…when you’ve got native code that could do math just bloody sitting right there? There are mobile-specific versions of SQLite, TensorFlow, and other data and ML tools now for Android; there’s absolutely no hard technical bound for any of this, just a fundamentally different way of thinking about the mobile world.
It really, really is the case this is better for user privacy. You wanted a real opt-out you privacy paranoiac? Great. Here’s an opt-out for you under this new paradigm: take your phone and throw it into the bay. You’ve really opted out now, unlike before.
Ads…who gives a shit? you might ask. Well, like it or not, advertising has a way of being the first industry to figure out many things.
Like porn, advertising is a ruthlessly pragmatic (and quantitative) business willing to adopt any technology that yields a minor edge. The same way that porn pioneered online payment and video-streaming when Amazon and Netflix weren’t even glimmers on the horizon yet, ads will be the first industry to undertake this complete refactoring of how your data is used. Consider all the data that your smart watch is currently ingesting about you—heart rate, location, blood oxygenation, sleep quality, even cardiac fibrillation—the biggest collection of human health data in history, all just sitting on your device and usable in a million different ways. It too will have to be managed via the device-first paradigm I sketch out above, except that the machine-learning model running on your gadget won’t be predicting clicks but heart attacks instead. It’s simply the ads team that will pioneer the technology because they’re most incentivized to do so, due both to regulation (thanks EU!) and immediate monetary incentives.
Are matters more interesting now?
Our 20-year-old data paradigm is simply dumb if you think about the problem from first principles, and the exact inverse of how you’d design a data ecosystem in our current mobile-first, in-app world. Which is why every company from Google to Apple, to anyone else daring (or foolhardy) enough to challenge them, will be designing everything to look like the second data-flow diagram above.
The EU and regulators? I give them at least 2-3 years before they figure out what’s going on2, and another couple years to figure out how to even begin to regulate the new architecture. By then it’ll be too late: the paradigm will have flipped and it’ll be on-device all day long. Again, the new architecture is much more supportive of current thinking around data privacy, legally if not exactly spiritually. The indispensable traffic in dollars for human attention will continue, even if in far more technically sophisticated form. Advertising, like life, always find a way.
My next post(s) will be about fancy-sounding technologies like differential privacy and federated learning, which make the data alchemy I gloss over here possible. Companies like Google and Apple have been low-key doing pure research in those fields to enable this eventual switch (here and here, respectively) for a while now.
I’ll also cover the more legal and philosophical questions around modern online privacy, and how privacy3 precedents from the world of locked doors and sealed letters need to adapt to the world of bits and database rows.
A future post will explore its significance, particularly what happens when a company deletes that key from the diagram. It’s as if the US government woke up one day and decided to cancel all social security numbers.
I found it interesting that a very knowledgeable-seeming Rep. Kelly Armstrong from North Dakota asked Google’s Sundar Pichai detailed questions about FLoC in the most recent congressional hearing pageantry (which Pichai mostly evaded by promising future white papers). Rep. Armstrong touched on a key issue that comes out of this re-architecting: to what extent does re-engineering the data flows to privilege privacy harm market competition and increase incumbent advantage? I would argue it does so significantly, and will address the issue in future posts.
The word ‘privacy’ in our modern form wasn’t used until 1814; the legal principle itself (in the sense we mean it here, not the Fourth Amendment cops-kicking-doors sense) was mostly invented by future SCOTUS justice Louis Brandeis in 1890. For what’s often touted as a fundamental human right, up there with life and liberty, there’s very little mention of it in any jurisprudence before the late 19th-century.
Wink if they also listen to our conversations.
This transition you are describing - to targeting and optimization happening on devices, using tons of locally stored data, which never leave the devices - reminds me of the thesis in "The Origin of Modern Consciousness and the Breakdown of the Bicameral mind."
(Pause, for "bong rip" sound effect)
The "bicameral mind" hypothesis was that people used to hear voices of 'the gods', and just took these literally, until sometime around the bronze age collapse, people realized these voices came from inside their heads. The argument sounds like cities and large scale human structures were initially "computed in the cloud" - as a result of these stories that bounced around, with cloud servers replaced by the cultural superorganism.
Moving all this optimization / computation data onto the devices (but still under cloud control!) starts to make the mobile devices themselves look ever more like people. The device looks even more like an extension of our own brains, this time with _somenone elses'_ values system encoded in it.
I would think one implication of all of this is a push to own more and more hardware.