
From privacy switch to privacy knob
How differential privacy is going to change how your data is used by Apple, Google, and others

As I hopefully elucidated in the previous post in this series, we’re on the verge of a radical change around how humans interact with their own data, as well as the Borg of cloud computing we’ve erected around ourselves. This seismic shift from cloud to on-device data will have massive and long-lasting repercussions on the engineering, business, and privacy legalities of mobile computing. In this post, we’ll talk (at a very high level) about some of the engineering challenges associated with the new approach, and the fancy data-science and model-building solutions1.
O, what a world of profit and delight,
Of power, of honour, of omnipotence,
Is promis'd to the studious artizan!
All things that move between the quiet poles
Shall be at my command…
-Christopher Marlowe, Doctor Faustus
This move toward on-device data and computation presents an enormous challenge to engineers and companies who depend on that data. It’s almost as if the American Board of Otolaryngology declared that, due to reasons of buccal privacy, all tonsillectomies must now be performed rectally rather than orally. That’s right, you have to go in the back way to snip them tonsils. Faced with that mandate, what do you do? Well, you build the world’s longest colonoscopic tools, and get really get good at operating via this (pun intended) ass-backwards approach. Is it a massive pain in the ass, for both you and patient? Of course it is, but vox bruxellae, vox dei!, at least when it comes to privacy regulation. Once you’ve figured out the rectal approach to privacy however, it’s actually not that big a deal and you’ve finally got the Belgian Eurocrats off your ass (for now at least).
Which is the entire point of the convoluted colonoscopic machinery we’re about to discuss.
To reiterate from the previous post, the challenge is twofold:
How do we do as much of the actual machine learning and optimization on the device itself so as to not have to move data off the phone?
Assuming we can’t do (1) for some class of problems, how do we take data off the phone while still maintaining certain privacy guarantees like not learning too much about you as an individual (or even some small group of users)?
Let’s tackle the second problem first, and I’ll illustrate the solution using the ‘Harvard Asshole Problem’.
Let’s say you’re a young associate on the trading desk at Goldman Sachs, and as with everyone on Wall Street, your worth as a human is determined by the value of your discretionary bonus at the end of the year. Since we’re proud members of the professional-managerial class whose only animating spirit is a narcissistic self-regard for our own rung on the status hierarchy, we want to know how well we’re pacing against our peers. After all, we need to assure ourselves the late nights and stress are worth it.
So we concoct the following protocol: Every associate takes their bonus number and prints it out in the same font, and tosses the slip of paper in a hat. Then someone averages the numbers in the hat and informs everyone of the average; now everyone knows where they stand versus the average, but nobody’s individual number was divulged.
Enter the Harvard Asshole: Mr. Asshole decides that he wants to know at least roughly where your bonus landed. So he arranges to take your contribution last, and then averages the bonuses before you toss yours in the pile, and right after2. Let’s say the average before you tossed in your slip was $100,000, and it was $101,000 immediately after your bonus was included in the total. Based on that alone, Mr. Asshole knows your bonus was higher than $100,000; if he has some idea of how many people total are in the basket, he can even approximate how much higher than the initial average your bonus was. A process that was supposed to grant you absolute privacy has now become leaky, allowing a hostile opponent to know things about you (or a set of people) they shouldn’t know.
How to fix this?
Instead of simply adding your bonus to the basket, I’m going to suggest you open Excel and use its random number generator RAND() to generate a random number between -10,000 and 10,000. This will generate a string of numbers somewhere between those two extremes, and (importantly) with an average expected value of 0 (i.e., the center point between the two extremes in what’s a symmetric distribution).
So run your random number generator over that -10,000/10,000 range, and just add whatever comes out to your bonus, and toss that into the ring instead. What you’re essentially tossing in is: bonus + random_number_between(-10,000, 10,000). Say the random number is -$8,000 and your real bonus is $105,000, so you put $97,000 into the basket instead.
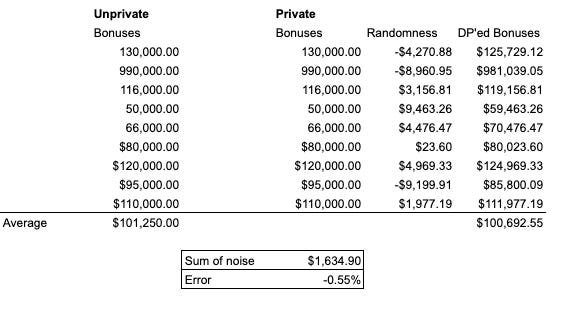
What happens when Mr. Asshole does his trickery now? Well, the average goes from $100,000….to something less than that after your contribution (we’re now averaging $100k with $97k, which reduces the average). Mr. Asshole think your bonus is lower than average when really it’s higher. A little bit of random noise added in to your data protects you from being snooped on.
Well, but doesn’t the overall average measurement suffer, kind of ruining the point of the entire exercise which was publicizing in an anonymous fashion the bonus numbers?
Less than you might think!
Remember, the average value of the numbers we draw from this uniform distribution is zero, which means the sum of a bunch of draws is noisily close to zero (and it gets closer the more numbers you draw). By this neat differential privacy trick, you’ve added noise to your data, but not really added much noise to the overall computation3.
How much noise do we add though? Well, that depends. If we’re really worried about an opponent using various hacks to suss out information about us, we could dump lots and lots of noise into our data: make the randomness range from -$100,000 to $100,000 instead of the $20,000-wide band we chose above. The downside of course would be that we’d also be adding more noise to the average estimate, reducing the quality of the calculation. Our notion of privacy has become a tradeoff between accuracy and security, a novel feature of a fairly novel right.
Note the subtle but absolutely critical change that’s happened here:
Privacy is no longer some binary switch, essentially the Boolean output of some legal flowchart logic, but in fact a variable parameter. By turning the noise knob on our differential privacy, we can essentially ask the user: so how much privacy do you want? Or more realistically, the system architect can ask themselves: ok, how much accuracy are we willing to sacrifice in our models for how much privacy offered to the user?
The good news is that with differential privacy, the privacy logic has been engineered to conform with how people actually view their own privacy. That is, not as some categorical summum bonum I’m never willing to erode even microscopically, nor the binary output of some convoluted logic dictated by law, but rather as a squishy blob, almost a reservoir of a commodity.
Lest this sound like a debate among medieval schoolmen about how many angels can fit on the head of a pin, Apple, one of the pioneering companies in this shift, has already caught flack for picking insufficient and inconsistent privacy noise parameters for its services. Public debate around privacy will have to level up in a big way to properly debate this form of privacy (which is why this post exists), but it won’t remain an academic topic for every long. Just as somewhat specialized privacy law has spawned an entire Privacy Industrial Complex of wonks, activists, ‘researchers,’ and regulators, differential privacy will do the same. Before long, ‘epsilon’ privacy parameters will be bandied about sanctimoniously in some heated congressional meeting.
But leave aside whatever new privacy camp-followers spring from this new paradigm, and consider what a revolution this is in the legal and technical framing of privacy as a concept.
(Trigger warning: techno-optimism)
The new privacy is very much in line with how people actually think about their privacy (though perhaps not how Eurocrat regulators do). The best formal thinking here is from Helen Nissenbaum, a Stanford computer science professor with a background in philosophy, whose Privacy in Context is a major reference work. I’ll summarize a lengthy and complex argument with a simple example:
You go to the doctor, and he makes a scan of some part of your body. Puzzled, he wants to share the image with another radiologist to see if that lump is really dangerous or not. You would of course consent to sharing that scan to receive better care; you’re trading a bit of privacy for greater utility within a rubric of confidentiality. Even if you’ve never even seen nor heard of this other radiologist, or they’re in another state or country, you’d opt in.
Now say the doctor sells that scan (and your patient meta-data) to a pharmaceutical company so they can better target you with drug ads. Suddenly, when you see the brain meds (or whatever) ads in your Twitter feed, you feel violated. The context in which you entered into a privacy exchange has been grossly upended. This is the ‘contextual’ in Nissenbaum’s argument (which she discusses with much more subtlety and detail).
The problem with the otherwise compelling contextual approach to twofold:
The context is often non-existent: What do centuries of Enlightenment philosophy, Anglo Saxon jurisprudence, or Judeo-Christian thought have to say about the privacy of my 23andme genomic data? My Goodreads reading data? What’s even the user-centric context about any of that? How about my smartwatch’s health data, probably the biggest or at least longest-running heap of health data about me? There isn’t a pre-existing privacy context to any of this.
The context of privacy expectation often changes. We used to dox everyone every year: it was called the phone book, and arrived on your doorstep. You couldn’t invent the phone book now under current privacy law if you tried.
On the flip side, nobody in the landline age would have signed up to be tracked by a device that more or less transmitted a live feed of your location and endless images of you to countless parties, some even unknown to you.
To take a more concrete example, when Facebook shipped Newsfeed in 2006, it caused a storm of outrage at what seemed a grievous breach in privacy. A year later, if Facebook had shut down Newsfeed there would have been riots on the streets. The context shifted very quickly (which was the moral argument behind their now retired mantra MOVE FAST AND BREAK THINGS). As technology whipsaws the human sense of self and our relationship to other humans, that context radically changes along with it.
Points 1 and 2 together mean that even in a nuanced and good-faith (rather than harshly ideological) approach to privacy such as that offered by Nissenbaum, we’re still making it up as we go along.
The good news is that with differential privacy, the privacy logic has been engineered to conform with how people actually view their own privacy. That is, not as some categorical summum bonum I’m never willing to erode even microscopically, nor the binary output of some convoluted logic dictated by law, but rather as a squishy blob, almost a reservoir of a commodity. That blob of privacy I’m willing to trade here or there in exchange for some amount of convenience, security or community. That’s how we’ve always done it, whether it’s the phone book or the Fourth Amendment. As with so many other aspects of the computation that’s taken over more and more of our lives, making the digital conform to the human (rather than vice versa) is the path to a more peaceful compromise.
In my final installment for this series, I’ll get into more historical and philosophical ruminations about privacy: what a shockingly modern concept it really is, and how online privacy is reverting to analog notions that far predate the internet.
The original scope of this post included the other broad class of privacy cleverness, federated learning. Due to length, I decided to cut it, but if enough people whinge about it via email I’ll post an addendum.
Clearly, the analogy is a bit contrived here in that a real-world Harvard Asshole could simply do something like dog-ear the slips of paper, or use sleight-of-hand to read your slip. The opponent I’m trying to sketch here is the formal one used in academic research whereby someone can run a given set of queries or functions over the database; in this case, it’s only the average() function. Our Harvard Asshole isn’t very inventive.
This is obviously a super simple example, and real-world problems around (say) coming up with a differential privacy model for advertiser metrics, not to mention matrix models, is considerably trickier. But it gives you a taste for the approach. A broader primer for a non-technical audience, with relevant privacy frameworks, is here; the definitive reference is Dwork and Roth.
There’s also a somewhat whimsical example by Apple around using differential privacy to protect your emoji data.
Just catching up on all your work and love this series! So clear and engaging
To your first footnote — yes please add the addendum. This is me whinging!